










Nemotron-4-340B
nvidia开源340B参数大模型
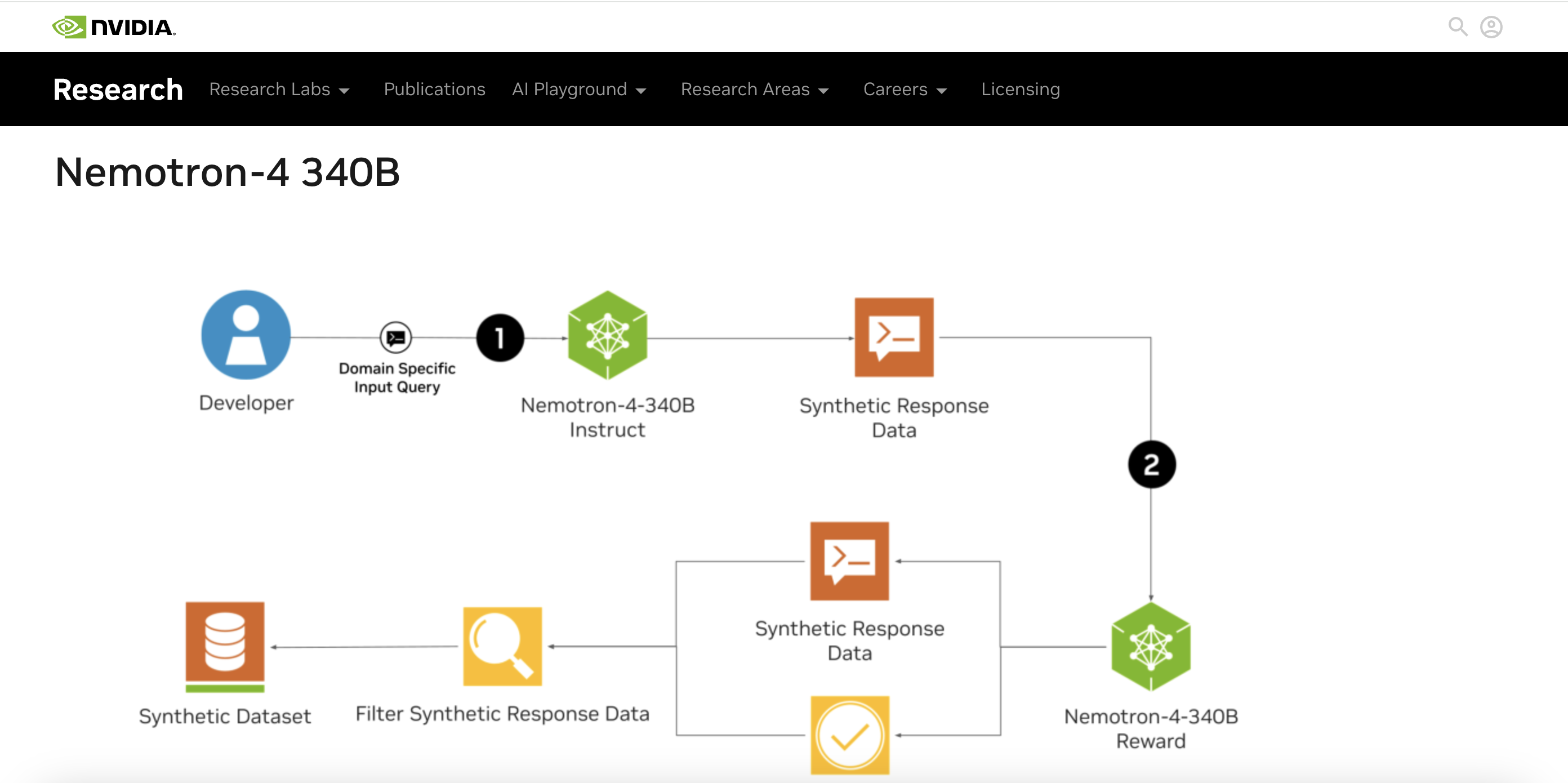
标签:开源AI模型3400亿参数 Nemotron-4-340B NeMo框架 NVIDIA TensorRT-LLM Transformer架构 合成数据生成 多语言模型 开源大模型 语言模型性能 高质量数据Nemotron-4-340B 是 NVIDIA 推出的一个多语言大型语言模型家族,包含基础模型(Base)、指令模型(Instruct)和奖励模型(Reward)。这些模型具有 3400 亿参数,经过了大规模数据的预训练,支持 4096 个 token 的上下文窗口,适用于生成高质量的合成数据,以用于训练和优化其他大型语言模型。
Nemotron主要特性
1.模型架构:
Nemotron-4-340B采用标准的基于Transformer的架构,结合了旋转位置嵌入(RoPE)和SentencePiece分词器,以提高模型在多种语言和编程语言上的表现。
2.预训练数据:
该模型在9万亿个文本token上进行了预训练,覆盖了广泛的自然语言和编程语言。
3.合成数据生成:Nemotron-4-340B专门设计用于生成合成数据,用于在训练数据不足的情况下生成高质量的合成数据,从而提升定制语言模型的性能。
4.多模型协作:
Nemotron-4-340B家族包含三个主要模型:
Base模型:提供基础的语言理解和生成能力,适合作为其他模型的基础。
Instruct模型:优化用于单轮和多轮对话,适用于生成多样化的合成数据。
Reward模型:用于评估生成的文本质量,通过对多个属性(如帮助性、正确性、一致性、复杂性和冗长性)进行评分,优化Instruct模型的输出。
Nemotron使用方法
NeMo框架:开发者可以使用NVIDIA的开源框架NeMo进行模型的训练和优化,该框架支持数据处理、定制和评估。
TensorRT-LLM:模型优化了对TensorRT-LLM的支持,通过张量并行性提高推理效率,适合大规模部署。
Nemotron应用场景
跨语言交流:Nemotron-4-340B提升了跨语言交流的能力,适用于翻译、内容生成等任务。
编程教育:模型在多种编程语言上的表现使其在编程教育和代码生成方面具有优势。
人机交互:通过生成高质量的合成数据,Nemotron-4-340B可以提升智能客服、虚拟助手等应用的效果。
Nemotron是否可以用于商用
模型可用于商业用途。
您可以自由地创建和分发衍生模型。
数据统计
相关导航







